1. 基本介绍
channel 意为通道,被设计于 Go 中不同协程之间的通信。它具有以下的特点:
- 并发安全;
- 可以在不同协程之间存储和传递数据;
- 先进先出;
- 具有阻塞和非阻塞两种执行方式。
通道的使用可谓非常简单,通过 <- 操作符就可以对通道进行发送和读取的操作,如下图所示:
// 1. 初始化 channel 对象
ch := make(chan int)
// 2. 将数据发送到 cahnnel
ch <- 1
// 3. 从 channel 中读取数据到 data 变量
data := <- ch
示例
举例来说,我们可以通过 channel 实现一个简单的生产者-消费者模型,代码如下:
func main() {
ch := make(chan int)
// 开启一个消费者协程,从通道中读取数据
go func() {
for {
fmt.Println("received:", <-ch)
}
}()
// 主线程充当生产者,往通道中发送数据
for i := 0; i < 3; i++ {
ch <- i
}
time.Sleep(time.Second)
}
输出如下所示,从输出的结构可以基本说明 channel 具备上面提到的的几个特点。得益于 channel 是并发安全的,在操作通道的过程中并不需要进行额外的加锁操作,在后续的源码解析中会介绍到它的实现。
received: 0
received: 1
received: 2
在上面的生产者-消费者模型代码中,通过 ch := make(chan int) 创建了一个无缓冲的 channel,意味着生产者每一次发送数据时都需要等待消费者接收完数据后才能继续往下执行(期间会被阻塞),说明无缓冲 channel 是同步的。但是同步不适用于大多数的场景,我们则可以创建一个带缓冲的 channel,相反它是异步的。带缓冲的 channel 只是在初始化时指定缓冲队列的大小,而无缓冲的 channel 则默认为 0:
func main() {
// 指定缓冲队列大小为 3
ch := make(chan int, 3)
go func() {
for {
fmt.Println("received:", <-ch)
}
}()
for i := 0; i < 3; i++ {
ch <- i
}
time.Sleep(time.Second)
}
对于熟悉 Java 的集合类熟悉的你来说,也许会发现有缓冲的 channel 其实和 BlockingQueue 类似,因此可以用 Java 的 BlockingQueue 来上面代码的相同逻辑:
public class Main {
public static void main(String[] args) {
int capacity = 3;
BlockingQueue<Integer> queue = new LinkedBlockingDeque<>(capacity);
new Thread(() -> {
while (!queue.isEmpty()) {
System.out.println(queue.poll());
}
}).start();
for (int i = 0; i < 3; i++) {
queue.offer(i);
}
}
}
而对于无缓冲的 channel 则虽然将 capacity 设为 1 实现类似同步读取和接收的功能,但是在 Go 的实现中,无缓冲的 channel 内部是不存在任何的数据结构缓存数据的,导致如果通道无人接收时将会被阻塞,而在 BlockingQueue 内部是由一个双链表来缓存数据的。
阻塞
如上我们得知,在一些情况下发送者和接收者是有可能被阻塞的,而针对有无缓冲的 channel 来说,由于缓冲队列的大小不同,所以两者的阻塞情况是有所不同的。
1、对于无缓冲 channel 来说
发送者阻塞发生在:channel 无人接收时,可以理解为没有绑定,如:
func main() {
ch := make(chan int)
go func() {
time.Sleep(2 * time.Second)
fmt.Println("Received:", <-ch)
}()
ch <- 10
// 发送者被阻塞,等待两秒后接收者开始接收数据时,才会执行下面的代码
fmt.Println("Sender finished.")
}
接收者阻塞发生在:channel 没有数据时,如:
func main() {
ch := make(chan int)
go func() {
fmt.Println("received:", <-ch)
// 接收者被阻塞,等待两秒后才通道有数据时,才会向下执行
}()
time.Sleep(2 * time.Second)
ch <- 10
}
2、对于有缓冲 channel 来说
发送者阻塞发生在:通道的缓冲队列已满时,如:
func main() {
ch := make(chan int, 3)
for i := 0; i < 3; i++ {
ch <- i
}
go func() {
time.Sleep(time.Second)
fmt.Println("received:", <-ch)
}()
// 现在通道里的元素个数为 3 ,等于缓冲队列的个数,通道为已满的状态
// 如果此时还往通道发送数据,将会被阻塞,直到接收者开始接收数据
ch <- 4
fmt.Println("sender finished")
}
而接收者阻塞发生在:通道没有数据时,如:
func main() {
ch := make(chan int, 3)
go func() {
// 由于发送者延迟了一秒钟发送数据,所以此时通道为空
// 如果此时从通道读取数据,将会被阻塞,直到发送者开始发送数据
fmt.Println("received:", <-ch)
}()
time.Sleep(time.Second)
ch <- 1
}
这种阻塞机制会被应用在编译检测,如果被检测出死锁将会 panic 异常。例如下面的代码中,发送者往无缓冲 channel 发送数据时,由于没有其他协程接收数据而被阻塞;随后接收者开始接收数据,但由于当前通道没有数据而被阻塞;造成了死锁:
func main() {
ch := make(chan int)
ch <- 2
go func() {
fmt.Println("received:", <-ch)
}()
}
// fatal error: all goroutines are asleep - deadlock!
解决的方法是将 ch <- 2 移到 go func(){...} 的下边。当然这种情况的死锁不会发生在有缓冲的 channel 中,因为原先发送的数据将会被存储到缓冲队列中,后续接收者将会从缓冲队列中复制数据。讲到这里,对 channel 有了基本的了解,但是还没有对 channel 的内部实现有真正的了解,如果上面的内容似懂非懂的话,相信你在和我一起剖析源码后,一定能恍然大悟。
2. 剖析源码
在剖析源码之前,我希望以减少贴长篇代码,专注于基本逻辑以及如何实现的方式来讲解。我会在一些地方标注源码的具体位置,如果你对代码感兴趣,可以点击链接仔细阅读。
channel 结构
channel 的结构体 hchan 可以在 runtime/chan.go 中找到,基本的属性如下:
type hchan struct {
qcount uint // 缓冲队列的数量
dataqsiz uint // 缓冲队列的大小
buf unsafe.Pointer // 缓冲队列的指针
elemsize uint16 // 元素类型
sendx uint // 发送索引
recvx uint // 接收索引
recvq waitq // 接收者等待队列
sendq waitq // 发送者等待队列
lock mutex // 互斥锁
...
}
type waitq struct {
first *sudog // 头节点
last *sudog // 尾节点
}
从这些属性就可以看出:
- 当
dataqsiz为 0 时,则为无缓冲 channel; - 由于有
sendx和recvx,说明缓冲队列是一个环形队列,这样可以有效地进行空间的重复利用; - hchan 本身是一个互斥锁,由于 channel 是先进先出的,所以需要在发送和接收时需要进行加锁的操作;
recvq和sendq为双向链表,分别用来存放阻塞的接收者和发送者。
为了知道在使用 > 关键字后底层调用了什么方法,我们需要从汇编代码中分析。首先将如下的内容写入 demo.go:
func main() {
ch := make(chan int)
go func() {
fmt.Println(<-ch)
}()
ch <- 1
}
然后运行:
$ go tool compile -N -l -S demo.go > out.txt
通过浏览 out.txt 比较发现,创建、接收、发送所对应的汇编代码依次为:
ch:= make(chan int) ------------ 0x0031 00049 (demo.go:8) CALL runtime.makechan(SB)
fmt.Println(<-ch) ------------ 0x0040 00064 (demo.go:10) CALL runtime.chanrecv1(SB)
ch <- 1 ------------ 0x0072 00114 (demo.go:12) CALL runtime.chansend1(SB)
Send
在汇编代码中,可以看到当执行 ch <- 1时,实际调用 chansend1,而又调用 chansend 并指定参数 block = true,说明该发送操作是阻塞的:
func chansend1(c *hchan, elem unsafe.Pointer) {
chansend(c, elem, true, getcallerpc())
}
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
...
}
在 chansend 完成了具体的发送操作,主要的步骤为:
- 如果往 channel == nil 的通道发数据,在 block = true 的情况下,将会被阻塞,否则直接返回,见 #143;
- 加锁,见 #183;
- 如果
recvq不为空,说明 Buffer 里为空(导致接收者被阻塞),则调用send直接发送给接收者并返回,见 #190; - 如果
recvq为空: - 阻塞协程被唤醒(由于其他的接收者读取数据),做一些后续的操作,见 #244。
在 send 方法内,则会调用 sendDirect 方法,直接将发送者协程栈中的数据直接复制到接收者协程栈中。为什么要这么做呢,这里有必要提一下 Go 的并发编程中很经典的一句话:
Do not communicate by sharing memory; instead, share memory by communicating.
译:不要通过共享内存的方式来通信,而是用通信的方式来共享内存。
如何理解呢?因为通过共享内存的方式来通信会导致并发不安全,即竞态条件。举例来说,下列代码内无法保证每次的输入都为期待的 1000,解决的办法是加锁实现同步:
func main() {
var wg sync.WaitGroup
cnt := 0
for i := 0; i < 1000; i++ {
wg.Add(1)
go func() {
defer wg.Done()
cnt++
}()
}
wg.Wait() // 等待所有的协程执行完毕
fmt.Println(cnt)
}
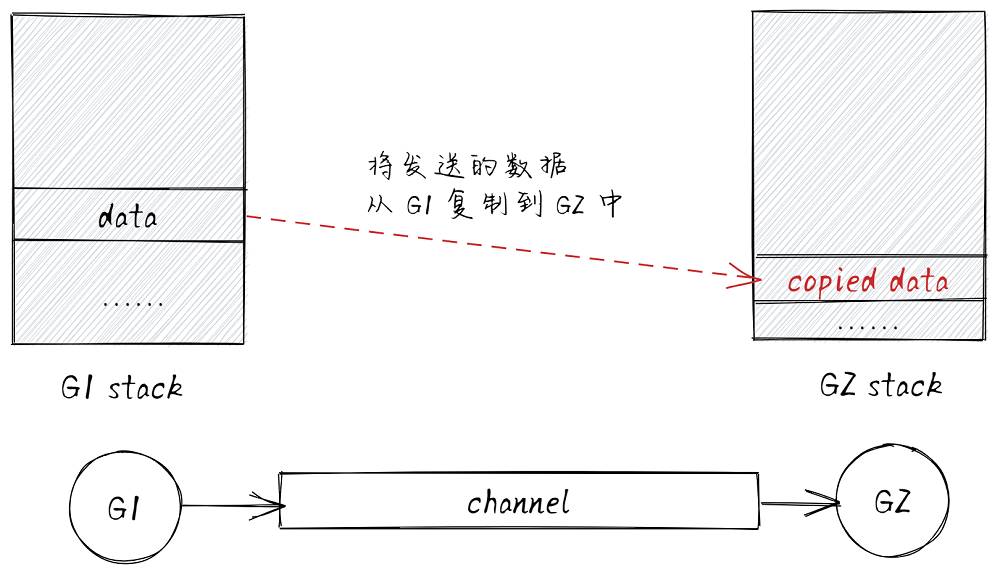
而后半句的「share memory by communicating」正是 channel 的实现,这里的 communicating 为复制数据。也就是说发送者协程 G1 和接收者协程 G2 通信时,G1 不是简单地将数据赋值给某个变量,然后 G2 再从变量中读取。实际的做法是将 G1 栈中要发送的数据复制到 G2 的栈中,达到共享内存的目的:
func sendDirect(t *_type, sg *sudog, src unsafe.Pointer) {
// src 为指向发送者协程 G1 栈的指针
// dst 为指向接收者协程 G2 栈的指针
dst := sg.elem
typeBitsBulkBarrier(t, uintptr(dst), uintptr(src), t.size)
// 复制内存
memmove(dst, src, t.size)
}
如下图所示:
Recv
接送数据 <- ch 的操作底层则是调用了 chanrecv1 ,又调用 chanrecv 并指定参数 block = true:
func chanrecv1(c *hchan, elem unsafe.Pointer) {
chanrecv(c, elem, true)
}
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
...
}
同样地,接收者在 chanrecv 完成了具体的接收操作,主要的步骤为:
- 如果往 channel == nil 的通道读数据,在 block = true 的情况下,将会被阻塞,否则直接返回,见 #429;
- 加锁,见 #460;
- 如果 channel 已经 close 并且没有数据,直接返回,见 #462;
- 如果
sendq不为空,则调用recv接收数据,见 #473; - 如果
sendq为空: - 阻塞协程被唤醒(由于其他的接收者读取数据),做一些后续的操作,见 #527。
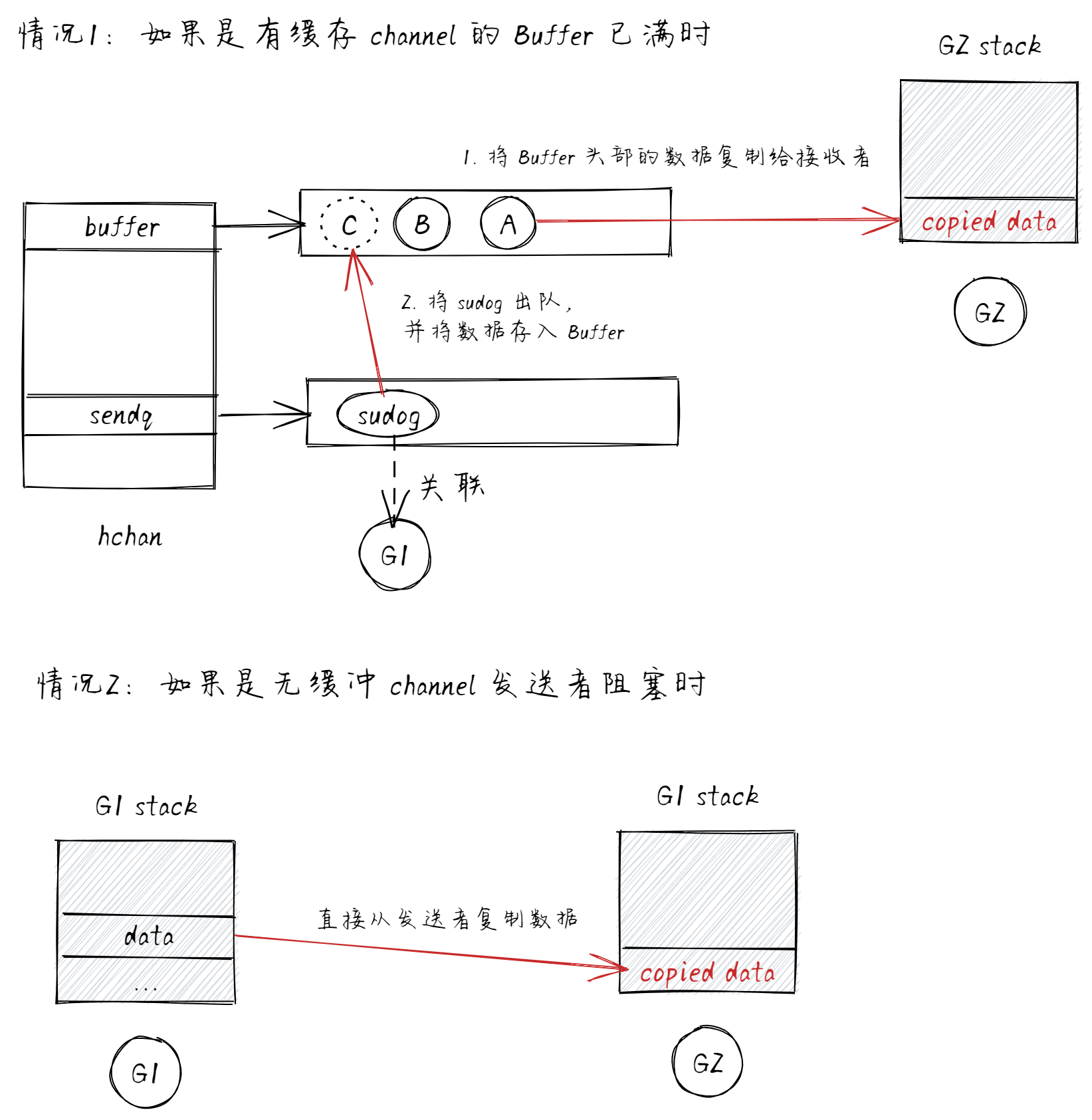
针对第 4 点来说,只有当 sendq 不为空,即 Buffer 已满时或无缓冲 channel 发送者被阻塞时,才会调用 recv 方法接收数据。而在 recv 方法内,针对这两种情况做出不同的逻辑:
- 如果是有缓存 channel 的 Buffer 已满时:将 Buffer 头部的数据复制给接收者,并将
sendq出队的sudog中的数据存入到 Buffer 的尾部,见 #575。 - 如果是无缓冲 channel 发送者阻塞时(channel 无人接收时):直接从发送者复制数据,见 #561。
如下图所示:
源码解析到这儿就结束了,当然这里只是对 channel 的发送和接收相关方法做了基本的介绍,有很多的细节并没有涉及到,也有讲的不对的地方,如果你感兴趣可以自行阅读源码,做进一步的了解。相信看完剖析源码后,你对前面所提到的一些知识都能很容易地解释了,不妨回头看看。
不得不说阅读源码有时也得「不求甚解」,了解设计思想和基本逻辑即可,不需要太注重每一行代码的功能和实现,否则会事半功倍。另外,由于源码的解析的确涉及方方面面,而且底层的实现也略微复杂,我只能通过我理解的方式进行讲解,同时也存在着很多不足。如果这篇文章能帮助你了解到这方面的知识,足矣。