前言
为什么会有这篇博客呢,主要是最近换了一家新公司,由于一些 Java 变化带来的感想或是使用上的体验和感受,下边的表格是我从之前到的公司到现在框架的变化:
| Previous | Now |
|---|---|
| Dubbo | gRPC |
| QMQ | Kafka |
| async-redis(internal) | Redisson |
| MyBatis | JOOQ |
| … | … |
对于像 Dubbo、QMQ 这类中间件的变化,其实感受并不是很大,原因可能是 Client 端的使用中并没有太大的区别,重点可能是在它们 Server 端的高可用、高性能的差别。
而对于像 Redis、MySQL 这类 Client 的变化,似乎感受比较深刻,新的 API、新的特性、新的体验。所以我想就这些框架,聊聊我的理解,以及它们的特性和实践。
Redisson
简单介绍
Redisson 在 Redis 的官网中所推荐的 Java Client 中,位居第一。 而它在在其官网是这么介绍它自己的:
Redis Java Client with features of In-Memory Data Grid.
所以我们可以发现,Redisson 并不是像我们常用的 Jedis 那样,是一个简单实现了 Redis 协议的 Client。它屏蔽了 Redis 的数据结构(虽然也可以通过底层 API,操作原始的数据结构),而是抽象出 50 多个对象,并基于 Redis 的基本数据结构来实现。
另一方面,Redisson 是基于 Netty 的,底层是 NIO 的线程模型。从源码也可以看到,它的方法基本实现都是 RFuture 来实现异步,而同步操作都是通过一个公共的线程池 commandExecutor 来完成回调。
protected final <V> V get(RFuture<V> future) {
return commandExecutor.get(future);
}
同时,它还原生支持 RxJava 和 Spring Reactor 的 API,让我们可以更好地完成异步编排。
特性
上边提到,Redisson 抽象出了 50 多个 Java 的数据结构,更多的可以参考 Redisson Github wiki。而在这里,我就不介绍某些数据结构的基本使用方式了,我更想说说 Redisson 它的特性,以及为什么应该选择它。
使用简便
这里的简便,不光是 API 比较简单,而是它巧妙通过让一个 Java 开发者最容易上手的方式:实现 JDK 原生数据结构的接口。
例如:Redis 的哈希表的数据结构,Redisson 将其抽象成了 RMap ,并实现了 java.util.Map 的接口,使得我们使用 Redisson 数据结构时,就像使用本地 Java Map 一般,似乎没有任何的学习成本。代码如下:
RedissonClient client = Redisson.create();
RMap<String, Integer> map = client.getMap("map");
// 添加元素
map.put("key", 0);
// 获取元素
int value = map.get("key");
// 判断元素是否存在
boolean exists = map.containsKey("a");
类似的还有很多:
| Redisson | JDK |
|---|---|
| RList | java.util.List |
| RSet | java.uitl.Set |
| RDeque | java.uti.Deque |
| RLock | java.util.concurrent.locks.Lock |
| … | … |
也是因为这种低的上手难度和成本,我将之前斗地主项目存储在内存中的 Room 数据使用 Redisson 的 RMap 数据结构进行重构,很平滑地就完成了迁移。
特殊的数据结构
另外,除了对 Redis 原生的数据结构简单的封装外。Redisson 基于这些简单的数据结构,实现了更为丰富并特殊的数据结构,方便我们更好地应用到业务场景中。
RMapCache
我们都知道,Redis 哈希表本身只支持 Key 级别的过期驱逐机制,而在某些业务场景中,我们只需要具备 field 级别的粒度的。虽然我们也有两种方式来实现:
- 延迟删除:将添加的时间戳记录在 value 或额外的结构中,在每次 hget 时先判断时间 gap 是否过期
- 主动清理:需要本地实现定时任务,定期轮询清理
两种方式实现都比较复杂,考虑的点也很多,而使用 RMapCache 则能简单地实现,如下代码:
RMapCache<String, Integer> cache = client.getMapCache("map-cache");
// 设置过期时间为 10 秒
cache.put("a", 1, 10, TimeUnit.SECONDS);
// 获取当前 field 的 TTL
int remainingSeconds = remainTimeToLive("key");
其原理则是使用额外的 zset 来记录所有 field 的最近更新时间:
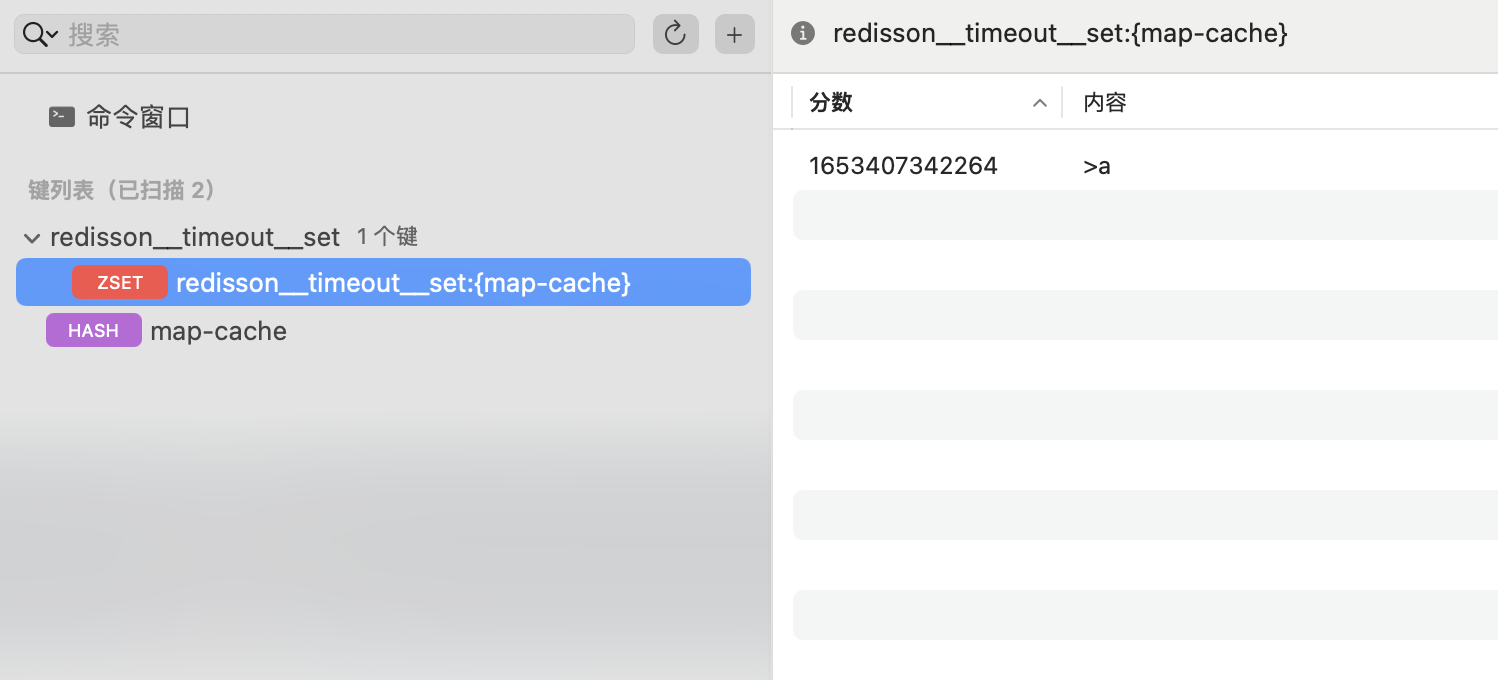
然后通过上面提到的主动清理的方式,在 MapCacheEvictionTask 定时任务中,使用 lua 脚本进行清理。
RLock
熟悉 Redis 的应该都了解,我们通常会使用 Redis 的 setnx 的特性,来实现简单的分布式锁。
但是,使用我们自己实现的简单分布式锁,常常会面临以下的一些问题:
- 原子性:需要保证 NX 和 EX 操作原子,虽然在 2.6.12+ 版本后,允许我们在可选参数中同时执行 EX 和 NX,但是稍微复杂的锁实现(如可重入)就无法保证了
- 续锁:由于避免死锁,所以往往会给锁添加过期时间,但如果某个线程占用锁期间过期,则不满足互斥
- 阻塞等待:某些场景下,我们想让分布式锁像 ReentrantLock 一样,如果竞争锁失败则阻塞等待,直到被唤醒重新获取锁
Redisson 的 RLock 则能同时满足上面功能,解决的方案分别是:
- 使用 Lua 脚本,来确保加锁操作的原子性,可以参考 tryLockInnerAsync 的实现
- 续锁方面,Redisson 则会通过 Watchdog 机制来自动续锁
- RLock 实现了 java.util.Lock 接口,即默认的 lock 方法就是会阻塞等待的
除此之外,除了 RLock 简单的可重入互斥锁实现之外,Redisson 还实现了其他的锁类型:
| Name | Class | Desc |
|---|---|---|
| 联锁 | RedissonMultiLock | 对多个 RLock 进行联合,适用于需要同时获取多个锁的场景 |
| 读写锁 | RReadWriteLock | 读写和写锁,适用于读多写少的场景 |
| 闭锁 | RCountDownLatch | 和 JUC 的 CountDownLatch 类似 |
| 红锁 | RedissonRedLock | Redis RedLock 的实现 |
| … | … | … |
总的来说,Redisson 是一个很适合你尝试的一个框架,能让 Redis 的作用进一步地放大!
jOOQ
简单介绍
首先,我们看下 jOOQ 的在 Github 介绍是什么:
jOOQ is the best way to write SQL in Java.
对比像传统的 JPA、Hibernate 等 ORM 框架,以及 MyBatis 这种半 ORM 框架来说,JOOQ 给自己的定义似乎不是一种 SQL 映射的 ORM 框架。
相反地,而是通过自己定义的 JOOQ DSL,通过 Java 编程的方式来书写 SQL:
- 一方面:解决了原生 SQL 的维护成本高的问题
- 另一方面:降低使用成本,让你感觉仍然是像在写原生的 SQL 语句。
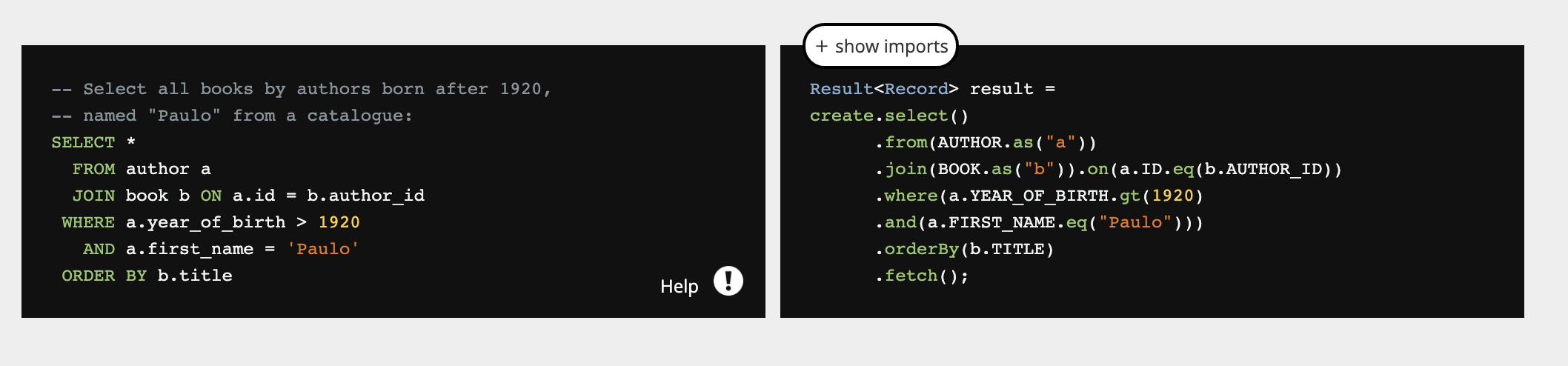
如下图官网给出的例子,使用 DSL API 并没有像 Hibernate 完全屏蔽数据库的操作,仍然可以参与到 SQL 语句的编写当中,这样做能极大提高灵活度:
特点
屏蔽方言的差异
我们知道:MyBatis 的最大有点在于它足够灵活,我们可以自己编写原生 SQL。但因此带来另一个问题:数据库方言的差异(例如 MySQL 和 SQLite),如果发生数据库的迁移,就可以需要涉及到 SQL 的修改。
但好在,JOOQ 的 DSL API 代码完全是通过 JOOQ Code generation 自动生成的,同时我们还可以在初始化 DSLContext 时,指定 SQLDialect 的类型:
DSLContext dslContext = DSL.using(connection, SQLDialect.MYSQL);
支持代码生成
前面提到,JOOQ 基础的 DSL API 是可以自动生成的,这样你就可以使用最原生的 JOOQ DSL 的方式来进行 SQL 操作。
但如果你想简化开发,那么你就可以在 jooq-codegen-maven 插件配置中,让其生成常用的 dao 接口实现:
<generate>
<pojos>true</pojos>
<daos>true</daos>
</generate>
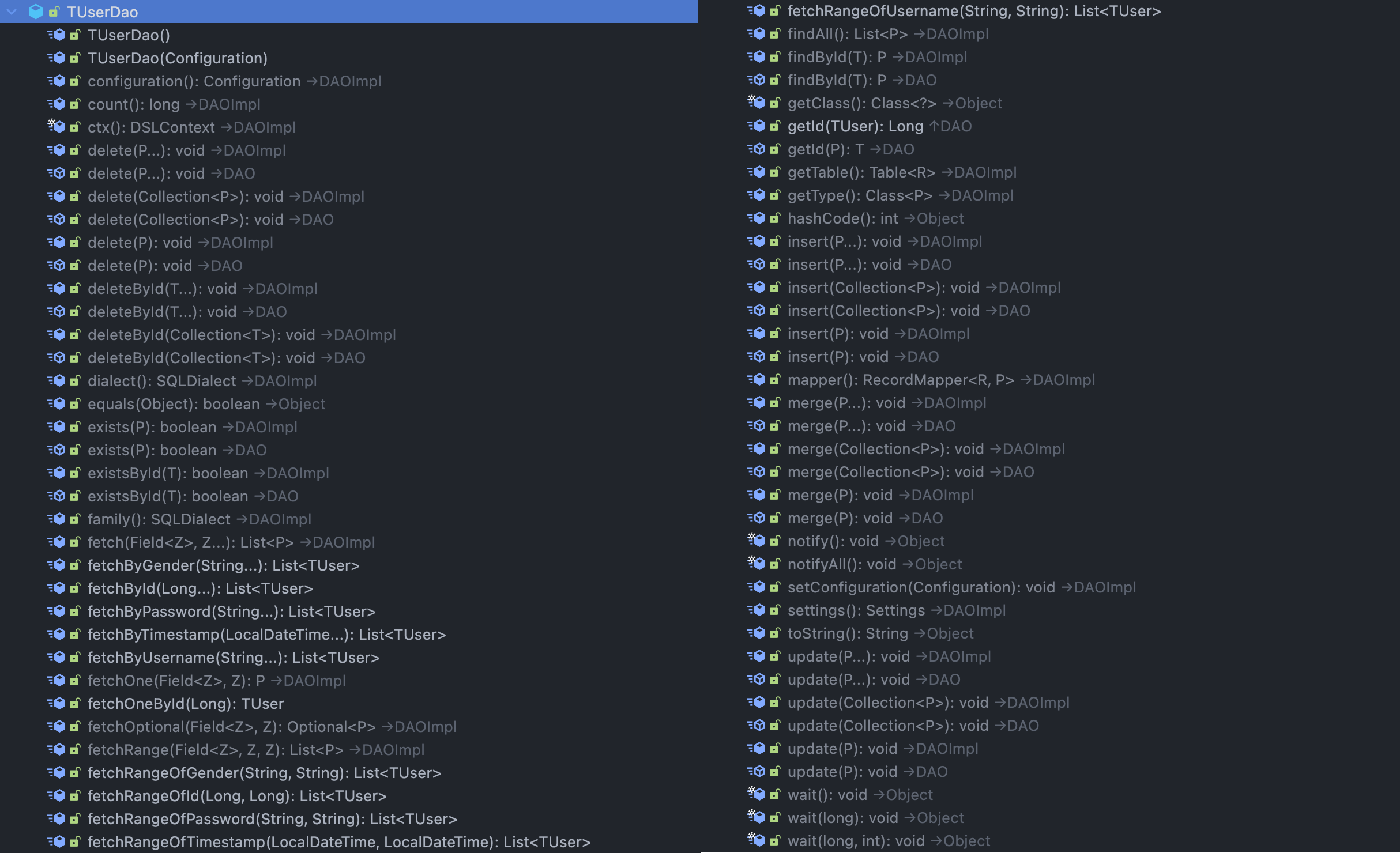
如下图所示,生成的 DAO 实现了基本的 CRUD,类似于使用 MyBatis 逆向工程的效果:
最佳实践
生成代码如何管理?
执行 jooq-codegen-maven 生成命令后:
$ mvn jooq-codegen:generate
会生成以下的文件:
└── org
└── example
└── demo
└── jooq
└── dao
├── DefaultCatalog.java
├── Demo.java
├── Keys.java
├── Tables.java
└── tables
├── TUser.java
└── records
└── TUserRecord.java
那这部分代码是否应当被 git 管理呢?我的建议是不需要:
- 并不影响正常的本地开发和 jar 包依赖
- 一次生成的代码变动,会干扰到 git 的变更记录
当然,这并没有任何的规范,而是相对比较好的方式。但是存在一个缺点,就是每次数据库变更时,都需要重新执行一次上面的 mvn 命令,重新生成代码。所以,我们将其生成的路径配置为 src/main/generated ,即:
<target>
<packageName>org.example.demo.jooq.dao</packageName>
<directory>src/main/generated</directory>
</target>
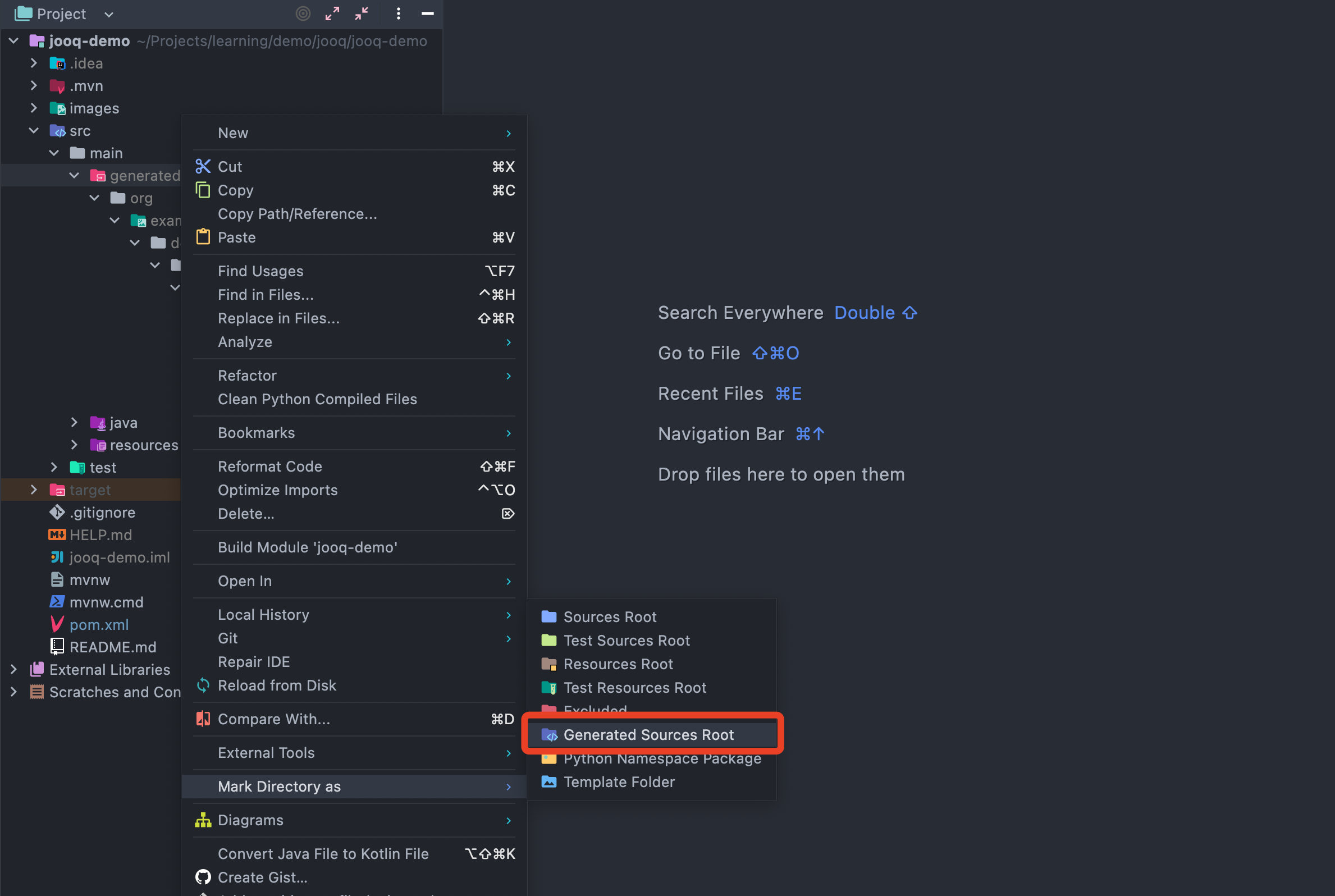
另外为了保证在 IDEA 中开发正常进行,我们需要将 src/main/generated 路径标记为 Generated Sources Root,否则将会找不到引用。如下图所示:
分库分表
由于 JOOQ 的操作都是通过 DSLContext 来执行的,而初始化时我们可以通过 set 来指定 DataSource,所以将转配的 ShardingDataSource Bean 设置即可:
DSLContext shardingDslCtx = DSL.using(new DefaultConfiguration()
.set(shardingDataSource)
.set(new Settings().withRenderSchema(false)) // 设置为 false,否则会影响到分库
.set(SQLDialect.MYSQL));
剩余的就可以交给 ShardingSphere 来完成,但是需要注意分表情况的 JOOQ 代码生成,假设 t_order 定义了三张分库的表,分别是:t_order_0、t_order_1、t_order_2,并且我们指定生成所有的表结构:
<database>
<name>org.jooq.meta.mysql.MySQLDatabase</name>
<inputSchema>my_db</inputSchema>
<includes>.*</includes>
</database>
那么生成的结果将会是:
// src/main/generated/org/example/demo/sharding/dao/tables
.
├── TOrder_0.java
├── TOrder_1.java
├── TOrder_2.java
└── records
├── TOrder_0Record.java
├── TOrder_1Record.java
├── TOrder_2Record.java
这样会导致两个问题:
- 不知道使用哪个 TOrder 表对象和对应的 Record 对象合适
- 不论使用其中哪一个,ShardingSphere 的分表都会失效(因为已经指定的某张表了)
比较好的解决方案是:我们重新创建一个 t_order 表,而在生成的配置中,我们只生成 t_order 表的相关代码即可,配置如下:
<database>
<name>org.jooq.meta.mysql.MySQLDatabase</name>
<inputSchema>my_db</inputSchema>
<includes>t_order</includes>
</database>
这样,我们只需要操作 TOrder 表对象和 TOrderRecord 即可:
├── TOrder.java
└── records
└── TOrderRecord.java
相关资料
关于 JOOQ 的基础教程,我推荐浏览 jOOQ系列教程,会有详细的 CRUD 的使用方法。当然,如果你是带有目的查询某个功能点,官网可能才是最好的资料。
另外,本文提到的一些相关 JOOQ 代码,可以参考:jooq-demo
一些思考
一直觉得,框架和编程语言一样,并不是束缚一位开发者的羁绊。大多数的知识,都能做到触类旁通。而了解和使用更多的框架,不但能享受不同框架带来的不一样的特性和使用感受,同时还能将最适合的框架,应用到最适合的项目、最适合的业务当中,这可能是框架的魅力了吧。
另外,我想起来之前面试时,一位面试官问我的一个问题:
你觉得,自研的框架和开源的框架相比,那个更好呢?
当时,我觉得自研的框架更为适合,因为它能够更好地适配公司的环境,也不用担心开源协议的限制。但现在我觉得,在开源和自研的框架,可能会做斟酌。因为拥抱开源,意味着能拥抱最前沿的技术,享受带来的全新的特性和体验,其中最大的可能还是 Redisson 给我带来的感受。
嗯,说到这里了,如果你有相关的想法与我分享,可以发送邮件到 1437876073@qq.com